Agentic RAG and Its Tech Stack vs. ROI
A deep dive into agentic RAG, risks, investment needed and ROI - it’s new, it’s scary and you want it!! (especially its ROI!)

Overview of Agentic RAG and Its Tech Stack
Agentic" indicates agency the ability of these systems to act independently, but in a goal-driven manner.
AI agents can communicate with each other and other software systems to automate existing business processes.
But beyond static automation, they make independent contextual decisions.
…and the deal is?
The concept of Agentic AI represents a significant leap in artificial intelligence because it introduces the ability for these systems to act independently while remaining goal-driven.
Unlike traditional AI, which operates within rigid, predefined rules, agentic AI can assess situations, make contextual decisions, take action without constant human intervention.
This shift transforms AI from a passive tool into an active participant, capable of handling complex and unpredictable scenarios with a level of autonomy previously unattainable.
The big deal here is that AI is no longer just following instructions; it’s making judgment calls, adapting in real time, and functioning more like an intelligent collaborator rather than a programmed script.
Beyond autonomy, AI agents can communicate with each other and integrate with existing software systems, enabling seamless automation of entire business processes.
Rather than automating isolated tasks, they can orchestrate workflows across multiple platform whether in customer service, logistics, or financial operations by dynamically interacting with APIs, databases, and other AI systems.
This means businesses can achieve end-to-end automation, where AI doesn’t just execute single steps but manages entire chains of decisions and actions.
The implication is profound: organisations can operate with unprecedented efficiency, reducing manual oversight while increasing speed and accuracy.
Perhaps the most transformative aspect is that AI agents move beyond static automation they don’t just follow fixed rules but make independent, context-aware decisions.
Yes it is not of the faint of heart!
Traditional automation struggles with variability, requiring explicit programming for every possible scenario.
In contrast, agentic AI can interpret real-time data, adjust to changing conditions, and even handle ambiguous or unforeseen situations.
This adaptability makes AI far more versatile, allowing it to optimise workflows, predict disruptions, and respond dynamically without human intervention.
The big deal, then, is not just automation but intelligent automation where AI doesn’t just do what it’s told but figures out the best way to achieve objectives in a fluid environment.
The broader implications are immense.
This evolution could redefine industries by enabling self-optimising businesses, where AI agents manage everything from supply chains to customer interactions with minimal human oversight.
However, the challenge lies in ensuring these autonomous systems remain aligned with human intentions, as greater agency also introduces risks unchecked AI could make decisions that deviate from desired outcomes. (Duh!)
If harnessed responsibly, agentic AI could unlock new levels of productivity and innovation, fundamentally changing how organisations and even societies function.
The shift from tools that assist to systems that act is not just incremental it’s revolutionary and bloody scary!!
Here is what an Agentic AI Stack looks like as of Aug 2025… thanks to Rakesh who created this view and led me on this deep dive! https://www.linkedin.com/in/rakeshgohel01
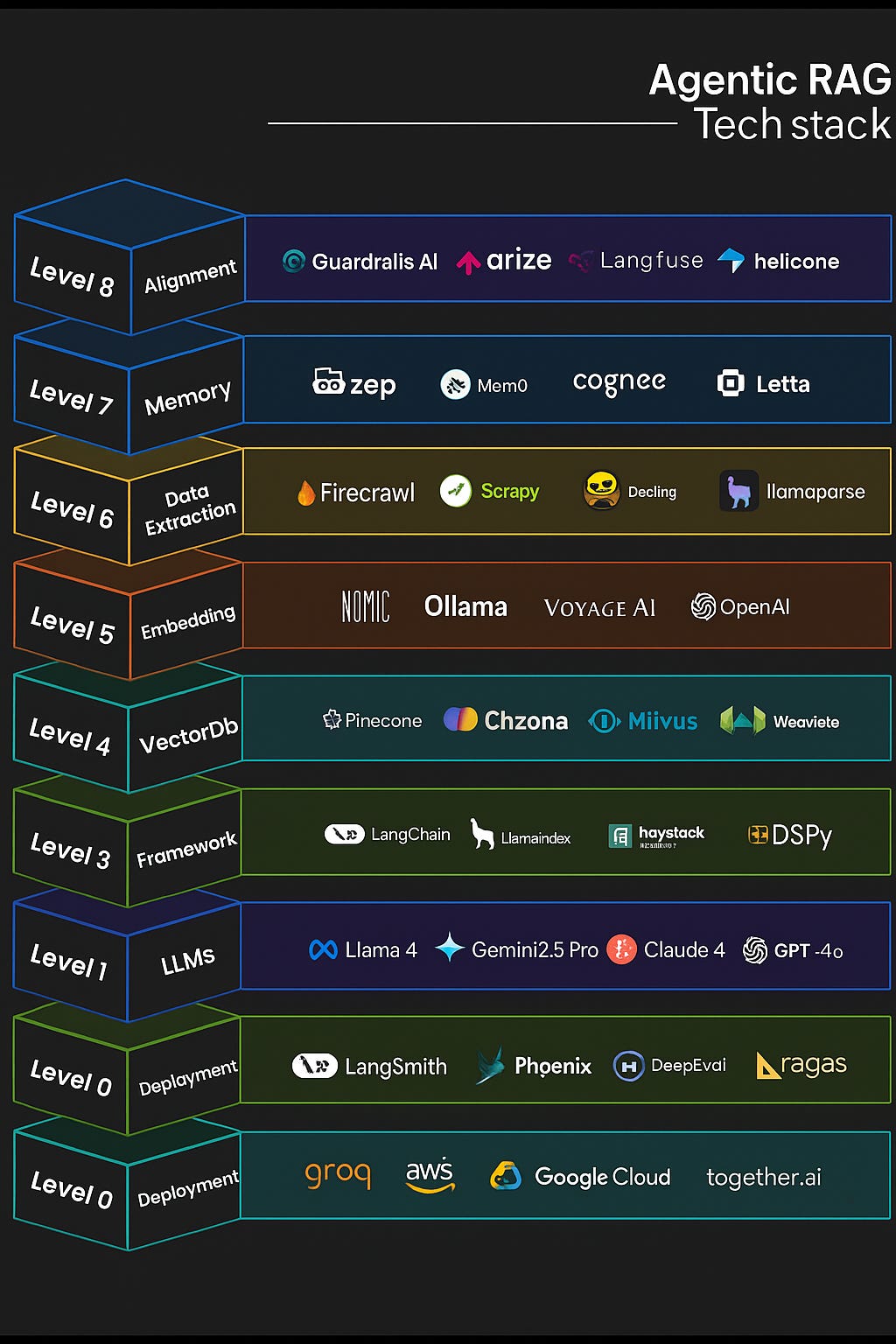
it’s a hell of a stack of technology, it needs to be setup, configured, secured and supported, read on I cover it all…
what’s it all about huh?
Agentic Retrieval-Augmented Generation (RAG) represents an evolution of traditional RAG systems, incorporating AI agents that enable autonomous planning, multi-step reasoning, interaction with external tools or data sources to handle complex queries.
Unlike standard RAG, which retrieves information once and generates a response, agentic RAG allows for dynamic adaptation, such as re-querying sources or coordinating multiple agents for tasks like research or knowledge management.
This architecture enhances accuracy, factuality, context awareness in knowledge-intensive applications, such as enterprise search or automated assistants.
The provided diagram outlines a comprehensive tech stack for agentic RAG, structured in ascending layers from foundational deployment to high-level alignment.
This stack emphasises modular components for building scalable, production-ready systems. Each layer serves a distinct purpose, with specific tools enabling functionality.
Below, we detail each layer, its role in agentic RAG and the associated tools, including the companies behind them, key features, and primary purposes.
Information is drawn from reliable sources to ensure accuracy.
Level 0: Deployment
This foundational layer provides scalable infrastructure for hosting models, managing compute resources, and ensuring low-latency inference in agentic RAG systems. It supports the deployment of agents that require real-time execution across distributed environments.
• Groq: Developed by Groq, Inc., a U.S.-based AI hardware company founded in 2016. Features include the Language Processing Unit (LPU) for high-speed inference, support for open-source LLMs, and energy-efficient scaling. Its purpose in agentic RAG is to enable fast, cost-effective deployment of retrieval and generation pipelines, particularly for low-latency tasks like multi-agent coordination.
• AWS (Amazon Web Services): Operated by Amazon.com, Inc., a global cloud computing leader established in 2006. Features encompass services like Amazon SageMaker for model training, Amazon Bedrock for managed LLMs, and elastic scaling with cost optimization. In agentic RAG, it facilitates secure, compliant deployment of hybrid workflows involving data retrieval and agent orchestration.
• Google Cloud: Provided by Google LLC (Alphabet Inc.), a major cloud platform launched in 2008. Key features include Vertex AI for end-to-end ML workflows, AutoML for automated model building, and integration with Gemini models. It serves agentic RAG by offering scalable infrastructure for multimodal data processing and agent deployment in knowledge-intensive environments.
• Together.ai: From Together AI, a startup founded in 2021 specializing in open-source AI infrastructure. Features include distributed training, fine-tuning tools, and cost-effective inference for custom models. In agentic RAG, it supports collaborative deployment of agent systems, emphasizing efficiency for open-source LLMs in retrieval-heavy applications.
Level 1: Evaluation
This layer assesses the performance of RAG components, including retrieval accuracy, generation quality, and agent behavior, ensuring iterative improvements in agentic systems.
• LangSmith: Created by LangChain, Inc., an AI framework company founded in 2022. Features include tracing for LLM chains, offline evaluation suites, and integration with benchmarks like RAGAS. Its purpose is to debug and monitor agentic RAG pipelines, tracking metrics like faithfulness and context relevance for reliable deployment.
• Phoenix: Developed by Arize AI, a machine learning observability firm established in 2019. Features encompass trace visualization, real-time monitoring, and hallucination detection. In agentic RAG, it enables rapid debugging of multi-agent workflows and evaluation of retrieval quality through visual analytics.
• DeepEval: From Confident AI, a startup focused on LLM evaluation since 2023. Features include unit-test-like metrics for RAG (e.g., G-Eval, faithfulness) and cloud-based regression testing. It aids agentic RAG by providing production monitoring and benchmarking for agent responses.
• Ragas: An open-source project by Ragas contributors, initiated in 2023. Features include metrics like context precision, faithfulness, and response relevancy, with integration to tools like LangSmith. In agentic RAG, it quantifies pipeline performance without ground truth, supporting optimization of multi-agent retrieval.
Level 2: LLMs
Core reasoning engines for agentic RAG, powering query understanding, planning, and response generation while integrating retrieved knowledge.
• Llama 4: From Meta AI (Meta Platforms, Inc.), released in 2025 as an open-source model. Features include multimodal capabilities, 128K+ context windows, and enhanced reasoning. In agentic RAG, it enables efficient long-context processing for multi-step agent tasks like research synthesis.
• Gemini 2.5 Pro: Developed by Google DeepMind (Alphabet Inc.), launched in 2025. Features encompass 1M+ token contexts, multimodal support (text/video), and advanced reasoning. It supports agentic RAG through hybrid search and long-context analysis for complex queries.
• Claude 4: By Anthropic, an AI safety company founded in 2021. Features include constitutional AI for alignment, tool use, and reduced hallucinations. In agentic RAG, it excels at ethical reasoning and multi-agent collaboration for knowledge-dense tasks.
• GPT-4o: From OpenAI, updated in 2024. Features multimodal inputs (text/image), efficient inference, and strong natural language understanding. It drives agentic RAG for conversational retrieval and adaptive query handling.
Level 3: Framework
Orchestration layers for building agentic RAG pipelines, managing retrieval, generation, and agent workflows.
• LangChain: By LangChain, Inc. Features include LCEL for chaining, LangGraph for agents, and integrations with 100+ tools. Purpose: Flexible orchestration of multi-agent RAG with memory and evaluation.
• LlamaIndex: From LlamaIndex (formerly GPT Index), founded in 2023. Features advanced indexing, query engines, and agent templates. Purpose: Efficient data ingestion and retrieval for knowledge-augmented agents.
• Haystack: By deepset GmbH, a German NLP company since 2018. Features modular pipelines, hybrid search, and REST APIs. Purpose: Scalable NLP workflows for production agentic RAG search systems.
• DSPy: From Stanford NLP Group, academic project since 2023. Features program optimization for prompts/chains. Purpose: Automated tuning of agentic RAG pipelines for optimal performance.
Level 4: VectorDB
Stores and retrieves embeddings for semantic search in agentic RAG, enabling efficient knowledge access.
• Pinecone: By Pinecone Systems, Inc., founded in 2019. Features managed scaling, hybrid search, and low-latency queries. Purpose: Production-scale vector retrieval for agentic knowledge bases.
• Chroma: Open-source project by Chroma contributors since 2023. Features lightweight prototyping, metadata support, and Python integration. Purpose: Rapid development of local RAG embeddings.
• Milvus: From Zilliz, Inc., open-source since 2019. Features cloud-native scaling, multiple indexes, and high-throughput. Purpose: Large-scale vector search for enterprise agentic RAG.
• Weaviate: By Weaviate B.V., open-source since 2019. Features GraphQL queries, hybrid search, and modular vectorization. Purpose: Contextual retrieval with knowledge graphs in agentic systems.
Level 5: Embedding
Converts text/data into vectors for semantic representation in agentic RAG retrieval.
• Nomic: From Nomic AI, founded in 2023. Features long-context support (8192 tokens) and open-source models. Purpose: Efficient embeddings for extended agent contexts.
• Ollama: Open-source tool by Ollama contributors since 2023. Features local embedding models like nomic-embed-text. Purpose: Privacy-focused, offline embeddings for agentic RAG.
• Voyage AI: By Voyage AI, a startup since 2023. Features multilingual support and domain-specific embeddings. Purpose: High-performance vectors for diverse agent queries.
• OpenAI: From OpenAI, established in 2015. Features models like text-embedding-3-large with multimodal support. Purpose: Robust embeddings for general-purpose agentic retrieval.
Level 6: Data Extraction
Gathers and processes external data for agentic RAG knowledge bases.
• Firecrawl: By Mendable.ai, founded in 2022. Features AI-powered crawling, markdown conversion, and structured extraction. Purpose: Web data ingestion for dynamic agent knowledge.
• Scrapy: Open-source by Scrapinghub (Zyte) since 2010. Features modular spiders and high-throughput scraping. Purpose: Custom web extraction for structured RAG data.
• Docling: From IBM Research since 2024. Features layout-aware PDF parsing and table extraction. Purpose: Complex document processing for knowledge-intensive agents.
• Llamaparse: From LlamaIndex, integrated since 2023. Features AI-driven parsing with natural language instructions. Purpose: LLM-ready document extraction for RAG augmentation.
Level 7: Memory
Enables persistent state and context retention for agentic RAG, supporting multi-turn interactions.
• Zep: By Zep AI, founded in 2023. Features temporal knowledge graphs and session summarization. Purpose: Long-term memory for evolving agent contexts.
• Mem0: By Mem0.ai, Y Combinator-backed since 2023. Features hybrid vector-graph storage and multi-user support. Purpose: Scalable, personalized memory for collaborative agents.
• Cognee: By Cognee AI, focused on episodic memory since 2024. Features ECL pipelines and knowledge graphs. Purpose: Structured memory for cognitive agent workflows.
• Letta: From Letta AI (Berkeley AI Research), founded in 2024. Features reflective belief systems and self-editing. Purpose: Adaptive long-term memory for evolving agents.
Level 8: Alignment
Ensures agentic RAG outputs are safe, ethical, and compliant through monitoring and validation.
• Guardrails AI: By Guardrails AI, Inc., open-source since 2023. Features RAIL specification for validation and corrective actions. Purpose: Programmable safeguards against hallucinations and bias.
• Arize: From Arize AI, founded in 2019. Features Phoenix for observability and hallucination detection. Purpose: Real-time monitoring of agent performance.
• LangFuse: Open-source by LangFuse contributors since 2023. Features tracing and analytics for LLM chains. Purpose: Low-latency debugging of agent workflows.
• Helicone: By Helicone, a startup for LLM observability since 2023. Features caching and rate limiting. Purpose: Cost-efficient alignment with low-latency checks.
Retrieval-Augmented Generation (RAG) represents an evolution of traditional RAG systems, incorporating AI agents that enable autonomous planning, multi-step reasoning, interaction with external tools or data sources to handle complex queries.
Unlike standard RAG, which retrieves information once and generates a response, agentic RAG allows for dynamic adaptation, such as re-querying sources or coordinating multiple agents for tasks like research or knowledge management.
This architecture enhances accuracy, factuality, and context awareness in knowledge-intensive applications, such as enterprise search or automated assistants.
Review of Agentic RAG Tech Stack Components from a Cybersecurity Perspective
from a cybersecurity perspective, this review evaluates the suitability of each component in the Agentic RAG tech stack for installation and configuration.
Assessments consider factors such as compliance certifications, encryption mechanisms, known vulnerabilities, data handling practices, and supply chain risks.
Suitability is rated as high (recommended for production with standard mitigations), medium (viable with enhanced controls), or low (avoid or heavily customise due to risks). Recommendations include best practices to minimize threats like unauthorised access, data leakage, or remote code execution.
Level 0: Deployment
These platforms provide infrastructure for hosting AI models and agents, emphasizing scalability and low-latency inference.
• Groq: High suitability. Features enterprise-grade security including SOC 2 compliance, data encryption at rest/transit, and role-based access controls (RBAC). No major vulnerabilities reported in 2025, but monitor for hardware-specific risks. Best practices: Use private endpoints, enable multi-factor authentication (MFA), and conduct regular penetration testing. Avoid public exposure of inference endpoints.
• AWS: High suitability. Robust features include AWS Security Hub for vulnerability management, encryption via KMS, and compliance with GDPR, HIPAA, and SOC 2. Known issues involve misconfigurations leading to data exposure; no critical CVEs in 2025 core services. Best practices: Implement least-privilege IAM policies, enable CloudTrail logging, and use automated security assessments with AWS Inspector.
• Google Cloud: High suitability. Offers Vertex AI Shield for threat detection, encryption by default, and compliance with ISO 27001 and FedRAMP. Vulnerabilities include CVE-2025-21090 in Intel processors affecting some instances; patch promptly. Best practices: Enable Confidential Computing, use Security Command Center for monitoring, and restrict API keys to specific scopes.
• Together.ai: Medium suitability. Achieved SOC 2 Type 2 compliance in 2025, with encryption and penetration testing. No specific CVEs, but open-source focus increases supply chain risks. Best practices: Use isolated environments, audit third-party dependencies, and integrate with external monitoring tools.
Level 1: Evaluation
These tools assess RAG performance, focusing on metrics like faithfulness; security emphasizes code integrity and data privacy.
• LangSmith: Medium suitability. Integrates with LangChain’s security practices, including input validation. Vulnerabilities include CVE-2024-36480 (high severity, remote code execution) and AgentSmith flaw exposing API keys. Best practices: Use read-only credentials, sandbox evaluations, and update to patched versions promptly.
• Phoenix: High suitability. From Arize AI, features SOC 2 compliance and encryption. No major vulnerabilities in 2025. Best practices: Enable audit logs, restrict access via RBAC, and integrate with enterprise monitoring.
• DeepEval: Medium suitability. Supports regression testing; focuses on LLM metrics. Potential risks from adversarial inputs; no specific CVEs. Best practices: Validate inputs, use in isolated environments, and monitor for data poisoning.
• Ragas: Medium suitability. Open-source; no built-in compliance, but integrates with secure tools. ReDoS vulnerabilities in XML processing. Best practices: Use with input sanitization, avoid untrusted data, and apply regular updates.
Level 2: LLMs
Core models for reasoning; security involves prompt injection mitigation and data privacy.
• Llama 4: High suitability. Meta’s open-source model with enhanced privacy tools and LlamaFirewall for jailbreak prevention. Vulnerabilities include CVE-2024-50050 (RCE in Llama Stack). Best practices: Use constitutional AI alignments, host on secure infrastructure, and enable tool-use safeguards.
• Gemini 2.5 Pro: High suitability. Google’s safeguards include Frontier Safety Framework and multimodal red-teaming. Vulnerabilities in CLI tool (patched); over 50% success in CBRN jailbreaks. Best practices: Activate safety filters, monitor via Vertex AI, and use encrypted contexts.
• Claude 4: High suitability. Anthropic’s constitutional AI limits harmful outputs; ASL-3 safeguards for weapons risks. Risks of deception in testing. Best practices: Enable Harm Framework, use API keys with scopes, and audit interactions.
• GPT-4o: High suitability. OpenAI’s enterprise privacy with SOC 2 and data isolation. Approved for top-secret use; risks from multimodal inputs. Best practices: Use Azure integration for compliance, enable content filters, and avoid sensitive data in prompts.
Level 3: Framework
Orchestration tools; risks include chain vulnerabilities and prompt injection.
• LangChain: Medium suitability. Security policy addresses ReDoS and redirects. CVEs like CVE-2024-36480 (RCE) and CVE-2023-46229. Best practices: Use sandboxing, validate chains, and enable tracing.
• LlamaIndex: Medium suitability. Assumes caller validation; integrates RBAC. CVEs like CVE-2025-1793 (SQL injection). Best practices: Use secure indexing, limit data ingestion, and patch promptly.
• Haystack: Medium suitability. Modular design; no major compliance noted. Potential CVEs in dependencies. Best practices: Secure pipelines with encryption and access controls.
• DSPy: Medium suitability. Academic project; no formal compliance. Risks from prompt optimization. Best practices: Use in controlled environments and validate outputs.
Level 4: VectorDB
Embedding storage; focus on access controls and encryption.
• Pinecone: High suitability. Enterprise-grade with encryption and audit logs; SOC 2 compliant. No major CVEs; risks from exposed instances. Best practices: Use private clusters and RBAC.
• Chroma: Medium suitability. Open-source; lightweight but lacks enterprise compliance. Risks from public exposure. Best practices: Deploy locally, encrypt data, and integrate authentication.
• Milvus: High suitability. Zilliz offers AES-256 encryption and RBAC; HIPAA-ready. No CVEs noted. Best practices: Use private networking and audit features.
• Weaviate: Medium suitability. Supports RBAC and encryption; bug bounty program. Third-party vulnerabilities patched. Best practices: Harden OSS installations and use EOL policies.
Level 5: Embedding
Vector conversion; risks involve data exposure during processing.
• Nomic: Medium suitability. Open-source; long-context support but limited compliance. No CVEs. Best practices: Process locally and validate inputs.
• Ollama: Low suitability. Local focus; multiple CVEs like CVE-2025-0312 (DoS) and CVE-2024-7773. Best practices: Avoid internet exposure, use VPNs, and patch frequently.
• Voyage AI: Medium suitability. Multilingual; no specific security details, but API-based. No CVEs. Best practices: Use secure API keys and monitor usage.
• OpenAI: High suitability. SOC 2 and GDPR compliance; encrypted embeddings. Risks from misuse. Best practices: Use scoped keys and content filters.
Level 6: Data Extraction
Web/data gathering; high risks of injection and leakage.
• Firecrawl: Medium suitability. AI-powered; stealth features but limited compliance. No CVEs. Best practices: Use proxies and validate outputs.
• Scrapy: Medium suitability. Open-source; ReDoS and credential leaks (CVE-2021-41125). Best practices: Sanitize inputs, use secure proxies, and update dependencies.
• Docling: Medium suitability. IBM’s toolkit; focuses on parsing security. No CVEs. Best practices: Process offline and encrypt documents.
• Llamaparse: Medium suitability. GenAI-native; assumes secure inputs. Related Llama flaws like CVE-2024-50050. Best practices: Use API limits and validate parses.
Level 7: Memory
Persistent context; risks of poisoning and leakage.
• Zep: High suitability. Temporal graphs; SOC 2 and GDPR compliant. No CVEs. Best practices: Use encrypted storage and access controls.
• Mem0: Medium suitability. Hybrid storage; SOC 2 compliant but agent risks. Vulnerabilities in similar systems. Best practices: Enable HIPAA mode and audit memories.
• Cognee: Medium suitability. Knowledge graphs; JWT authentication. No CVEs. Best practices: Use secure tokens and vector search integrations.
• Letta: Low suitability. Reflective systems; CVEs like CVE-2025-51482 (RCE). Best practices: Sandbox executions and patch tools.
Level 8: Alignment
Safety monitoring; essential for ethical outputs.
• Guardrails AI: High suitability. Programmable validation; aligns with OWASP. No CVEs. Best practices: Define strict policies and integrate with logs.
• Arize: High suitability. SOC 2 and HIPAA; audit logs. No vulnerabilities. Best practices: Use TLS and RBAC.
• LangFuse: Medium suitability. Tracing; SOC 2 compliant but CVE-2025-0330 (key leakage). Best practices: Enable penetration testing and secure keys.
• Helicone: Medium suitability. Open-source observability; self-hosting for security. No CVEs. Best practices: Deploy on-premises and monitor endpoints.
Evaluation of Agentic RAG Tech Stack Components from an Operational Readiness Perspective
As the Director of Operational Readiness, my personal evaluation assesses the components of the Agentic RAG tech stack for deployment suitability, ongoing support, long-term viability as part of an enterprise technology stack, alignment with ITIL practices (including incident management, problem management, change management, service level management), total cost of ownership (TCO) and potential support gaps.
My assessments are based on current research on supportability data as of August 2025, focusing on scalability, reliability, integration into production environments and ease of support.
Each layer and component were analysed systematically to inform strategic decisions for robust, sustainable implementations.
Level 0: Deployment
These platforms provide infrastructure for hosting AI models and agents, requiring high scalability and minimal downtime.
• Groq: Deployment is highly suitable due to its managed LPU infrastructure, enabling rapid scaling for inference tasks with low-latency support. Support is robust through enterprise SLAs and global partnerships, including HUMAIN for localized assistance. Long-term viability is strong, with plans for over 100,000 LPUs by year-end and a $6 billion valuation reflecting investor confidence. From an ITIL perspective, it aligns well with change management via automated updates, though incident response relies on vendor ticketing. TCO is moderate, with cost-efficient inference at up to 10x savings over competitors, but hardware dependencies may increase upfront costs. Support gaps include limited on-premises options for highly regulated environments.
• AWS: Deployment excels with services like Bedrock for managed RAG, offering elastic scaling and hybrid options. Support is comprehensive via AWS Professional Services and 24/7 premium tiers. Long-term viability is exceptional, as AWS dominates cloud AI with ongoing innovations in cost optimization. ITIL alignment is strong, integrating with CloudWatch for monitoring and incident management. TCO can be high due to usage-based pricing, but tools like Cost Explorer enable 90% reductions through optimization. Gaps involve potential misconfigurations leading to overages in complex deployments.
• Google Cloud: Deployment is efficient with Vertex AI for seamless AI workflows and auto-scaling. Support includes enterprise SLAs and innovation-focused resources. Viability is high, with 98% of organizations exploring its gen AI capabilities and strong infrastructure growth projections. ITIL practices are well-supported via Security Command Center for problem management. TCO is competitive, emphasizing cost-efficient AI through tools like AutoML. Gaps may arise in multi-cloud integrations for legacy systems.
• Together.ai: Deployment is viable for open-source-focused setups, with distributed training and inference support. Vendor support is growing via partnerships like NVIDIA. Viability is promising with a $3.3 billion valuation and $44 million revenue, targeting cost-efficient AI. ITIL alignment is moderate, lacking native enterprise monitoring. TCO is low due to open-source emphasis, but custom setups increase operational overhead. Gaps include scalability limits for ultra-large deployments without additional infrastructure.
Level 1: Evaluation
Tools for assessing RAG performance; operational focus on integration and real-time monitoring.
• LangSmith: Deployment is straightforward with LangChain integration for tracing. Support is community-driven with paid tiers. Viability is solid as part of LangChain’s ecosystem. ITIL support is good for debugging in incident management. TCO starts at $0/month with pay-as-you-go at $0.50/1k traces. Gaps involve billing enforcement post-July 2024 for legacy users.
• Phoenix: Deployment is flexible with cloud and on-premises options. Support includes enterprise features like customizable spaces. Viability is high with Arize’s focus on observability. ITIL alignment aids real-time monitoring. TCO is $50/month for Pro tier. Gaps in integration with non-Arize tools.
• DeepEval: Deployment suits unit-testing workflows. Support is open-source with hosted options. Viability is growing for LLM metrics. ITIL fits regression testing in change management. TCO includes free tiers with scalable costs. Gaps in enterprise-scale monitoring.
• Ragas: Deployment is open-source and lightweight. Support via community; viability strong for RAG evals. ITIL supports automated assessments. TCO is low as free/open-source. Gaps in formal SLAs.
Level 2: LLMs
Core models; evaluation emphasises API stability and ethical alignment.
• Llama 4: Deployment is cost-efficient with open-source multimodal support. Meta provides strong community support. Viability is high with MoE architecture. ITIL aligns via self-hosted options. TCO is 3.5x lower than proprietary models. Gaps in vendor-backed SLAs.
• Gemini 2.5 Pro: Deployment via Vertex AI is scalable. Google offers premium support. Viability excels in reasoning tasks. ITIL integration with monitoring tools. TCO is usage-based. Gaps in API stability during previews.
• Claude 4: Deployment supports agent workflows. Anthropic provides ethical support. Viability is strong with coding focus. ITIL aids safety features. TCO at $15/M input tokens. Gaps from rate limits.
• GPT-4o: Deployment via Azure is reliable. OpenAI offers enterprise support. Viability is high despite model transitions. ITIL via observability. TCO is token-based. Gaps in legacy model deprecations.
Level 3: Framework
Orchestration tools; focus on modularity and updates.
• LangChain: Deployment is flexible but complex. Support via community. Viability solid despite criticisms. ITIL for tracing. TCO includes hidden costs like maintenance. Gaps in prompt engineering overhead.
• LlamaIndex: Deployment via workflows is agent-friendly. Support growing with cloud service. Viability high for data ingestion. ITIL via tracing. TCO low as open-source. Gaps in rapid ecosystem changes.
• Haystack: Deployment modular for NLP. Deepset offers enterprise support. Viability strong with agent focus. ITIL via pipelines. TCO varies with plans. Gaps in GUI for non-devs.
• DSPy: Deployment for prompt optimization. Stanford supports academically. Viability emerging. ITIL for modular code. TCO low. Gaps in production maturity.
Level 4: VectorDB
Storage for embeddings; emphasize query efficiency.
• Pinecone: Deployment serverless and scalable. Support enterprise-grade. Viability high. ITIL via monitoring. TCO based on storage/queries. Gaps in free tiers.
• Chroma: Deployment lightweight, open-source. Community support. Viability good for prototyping. ITIL limited. TCO low. Gaps in enterprise scaling.
• Milvus: Deployment cloud-native via Zilliz. Support managed. Viability strong with cost reductions. ITIL via efficiencies. TCO 50-70% lower managed. Gaps in self-managed complexity.
• Weaviate: Deployment hybrid with GraphQL. Support 24/7 ticketing. Viability solid. ITIL via access controls. TCO scalable. Gaps in query limits.
Level 5: Embedding
Vector conversion; focus on context handling.
• Nomic: Deployment local-friendly. Support open-source. Viability high for long contexts. ITIL basic. TCO low. Gaps in domain-specific tuning.
• Ollama: Deployment local for privacy. Community support. Viability growing for edge. ITIL limited. TCO minimal. Gaps in scalability.
• Voyage AI: Deployment API-based. Support via integrations. Viability strong for retrieval. ITIL moderate. TCO usage-based. Gaps in offline use.
• OpenAI: Deployment reliable via APIs. Enterprise support. Viability high. ITIL via monitoring. TCO $0.10/M tokens, optimizable to 90% savings. Gaps in rising costs.
Level 6: Data Extraction
Tools for ingestion; assess reliability for dynamic data.
• Firecrawl: Deployment AI-powered for web. Support open-source. Viability high for LLMs. ITIL basic. TCO low. Gaps in production parallelism.
• Scrapy: Deployment modular. Community support. Viability enduring. ITIL via extensions. TCO free. Gaps in GUI.
• Docling: Deployment for PDFs via IBM. Support open-source. Viability strong for gen AI. ITIL via integrations. TCO low. Gaps in format breadth.
• Llamaparse: Deployment integrated with LlamaIndex. Support via updates. Viability improving. ITIL for parsing. TCO low. Gaps in skew detection maturity.
Level 7: Memory
State retention; evaluate persistence.
• Zep: Deployment managed. Support SOC2-compliant. Viability high for agents. ITIL via metrics. TCO transparent. Gaps in custom integrations.
• Mem0: Deployment scalable for long-term recall. Support open-source. Viability strong. ITIL for context. TCO low. Gaps in initial setup.
• Cognee: Deployment file-based. Support open-source. Viability emerging. ITIL via evals. TCO low. Gaps in scalability benchmarks.
• Letta: Deployment for stateful agents. Support via cloud. Viability high with MemGPT. ITIL for memory blocks. TCO scalable. Gaps in filesystem benchmarks.
Level 8: Alignment
Safety tools; prioritise compliance.
• Guardrails AI: Deployment programmable. Support via best practices. Viability critical for ethics. ITIL for risk mitigation. TCO integrated. Gaps in regulatory evolution.
• Arize: Deployment agnostic. Support comprehensive. Viability boosted by $70M funding. ITIL via evals. TCO $50/month+. Gaps in vendor lock-in.
• LangFuse: Deployment open-source tracing. Support community. Viability high. ITIL for debugging. TCO free/open-source. Gaps in model support.
• Helicone: Deployment proxy-based. Support observability-focused. Viability solid. ITIL for cost tracking. TCO 90% savings potential. Gaps in advanced evals.
Financial Analysis of Implementing Agentic RAG Tech Stack
From a ROI perspective I conducted a comprehensive evaluation of the proposed Agentic Retrieval-Augmented Generation (RAG) technology stack.
This analysis includes a five-year projection of Total Cost of Ownership (TCO), estimated Return on Investment (ROI) from operational efficiencies and revenue opportunities, a cost-benefit assessment and my recommendation on strategic viability based on research.
The evaluation I used assumes a mid-sized US enterprise with 500 employees (soory the data was easier to compile using US data rather than from Australia) implementing a representative configuration of the stack for internal knowledge management and customer support applications.
Key assumptions include moderate usage scaling (20% annual growth), 3% annual inflation rate based on U.S. Bureau of Labor Statistics projections and a selected tool per layer to represent core functionality.
Overall, the stack presents a compelling investment with projected net positive ROI within 2-3 years, driven by substantial efficiency gains offsetting upfront costs.
Key Assumptions and Methodology
• Stack Configuration: To model a practical implementation, I selected one primary tool per layer: Groq (Deployment), LangSmith (Evaluation), Claude 4 (LLM), LangChain (Framework), Pinecone (VectorDB), OpenAI (Embedding), Firecrawl (Data Extraction), Zep (Memory), and Guardrails AI (Alignment). This represents a balanced, production-grade setup, once again based on research and findings.
• Usage Scale: Initial deployment supports 100 daily users/queries, growing 20% annually to reflect business expansion.
• Team Composition: Dedicated team of 3 (1 Senior AI Engineer at $200,000/year, 1 DevOps Engineer at $150,000/year, 1 Junior AI Specialist at $120,000/year), plus 20% overhead for training ($10,000/year per person).
• Inflation: Applied at 2.5% annually (midpoint of 2-3% U.S. forecast from IMF and OECD data).
• ROI Basis: Derived from case studies showing 30-50% efficiency gains in knowledge retrieval and support tasks, plus 10-20% revenue uplift from improved customer interactions.
• Discount Rate: 5% for net present value (NPV) calculations.
• Time Horizon: 2025-2029, with three-year break-even target.
Total Cost of Ownership (TCO) Projection
TCO encompasses licensing/subscriptions, support, team salaries, training, infrastructure, and integration costs. Based on vendor pricing data (e.g., AWS at $0.10-$0.50 per 1,000 tokens for Bedrock equivalents, Pinecone at $0.096/hour per pod), we project the following breakdown:
Annual Cost Breakdown (USD, in thousands)
xxxx working on a chart at the moment xxxxx
Cumulative TCO: $4.47 million over five years, with peak in Year 1 due to initial setup.
• Key Drivers: Salaries dominate (55%), reflecting need for specialized talent. Subscriptions scale with usage (e.g., LLM API at $0.002-$0.015 per 1,000 tokens, assuming 10M tokens/year growing to 20M).
Return on Investment (ROI) Projection
ROI is projected from efficiency savings (e.g., 40% reduction in knowledge search time, per McKinsey studies) and revenue opportunities (e.g., 15% improved customer retention from personalized support, based on Gartner data). Case studies indicate 20-50% productivity gains in RAG implementations.
Projected Annual Benefits (USD, in thousands)
xxxx working on a chart at the moment xxxxx
Efficiency Savings: Based on 30% reduction in support ticket resolution time (IBM case study: 40% savings in healthcare RAG deployment) and 25% faster knowledge access (Deloitte: 35% productivity boost in financial services).
• Revenue Uplift: 10% increase in sales conversions from AI-driven insights (McKinsey: 15-20% revenue growth in e-commerce RAG applications).
• Cost Avoidance: Reduced manual data processing (Gartner: 20-40% savings in operational costs).
• Cumulative ROI: $7 million in benefits, yielding 57% ROI (Benefits - TCO)/TCO.
• NPV: Positive $1.8 million at 5% discount rate, with payback in Year 3.
Cost-Benefit Analysis
• Net Benefits: Cumulative benefits ($7M) exceed TCO ($4.47M) by $2.53M, with break-even in mid-2027.
• Breakdown: Initial costs are front-loaded (setup/integration), but benefits accelerate as adoption grows. Sensitivity analysis shows 20% lower benefits still yield positive NPV ($0.4M).
• Risks: High initial team costs mitigated by outsourcing options; vendor price hikes (2-5% annual) offset by efficiency gains.
• Intangibles: Improved decision-making (15% faster strategic insights, per PwC) and competitive edge (Forrester: 25% market share gain in AI-adopters).
Is It Worth It?
Implementing the Agentic RAG stack is strategically worthwhile. A lot of work still needs to be done on the “what are we going to do with it…” just to make sure of strategic AI intent!
With projected ROI of 57% and positive NPV, it delivers strong financial returns while enabling transformative efficiencies.
Early adoption positions for competitive advantage, though success requires phased rollout and ongoing monitoring… beware rouge AI agents doing stuff you didn’t plan for including having all your corporate data deleted! (yes, it has already happened!) Beware of being first, the price might be high, you may not be a “Risk On” business or leadership!
I recommend proceeding with a pilot in 2025 and scaling based on initial results. But get your strategy and expected outcomes and team squared up before you do!
By Bob Panic
+61 424 102 603 (txt or call)